Compilers and Factories
By Peter Miller
<pmiller@opensource.org.au>
Abstract
The techniques presented in this paper came about from a project
where I knew in advance that I wanted to build at least two tools
out of a single grammar. I wanted to translate an
application-specific language into C, and I also wanted a
pretty-printer. This is often done with two separate grammar
files (using Yacc, these are "dot Y" files) which differ not in
syntax but in the semantic code added to each grammar production.
Was it possible to have a single grammar file and use it in two
different tools? Parsing theory is one of the most powerful
collections of tools available to a programmer. It allows us to
turn complex input structures into structured data
representations more amenable to manipulation and analysis. The
theory is often taught with recursive descent parsers first, and
then moving on to parser generator tools, such as Yacc. These
tools permit a greater level of complexity, and more rapid
comprehension and maintenance. While these tools simplify the
task of writing a grammar recognizer, they have little effect on
the complexity of the subsequent processing performed on the data
content.
One of the most difficult things about parser
generator tools is beautifully demonstrated by the GNU C
Compiler's grammar specifications. The actual grammar is
visually overwhelmed by the sheer quantity of C code attached to
each production. It is not uncommon to have a strict separation
of the grammar specification, and have it call an external
function for each production, and to collect these functions into
one (or more) separate source files. In essence, one is a Yacc
file, and one is a C file.
But something interesting happens
when you make them methods of a single class, rather than
functions. When mixed with simple polymorphism (make them all
virtual) it becomes possible to leave the grammar untouched, and
yet derive completely different content processing classes.
Once coded, it becomes apparent that each method looks
suspiciously like a factory method. That is, it is given
arguments, and asked to return (for example) an expression node
for addition, when the infix plus operator is parsed.
Factories are interesting because they provide a powerful way of
thinking about things you know (and want to know) nothing about,
or very little about. This amorphous data hiding (not just
simple encapsulation) is what gives the technique its power.
In the context of grammars, the use of factories means that the
expression node for addition can print a plus symbol, and the
compiler can produce different ones for integer addition, real
addition, and so on. More tools results in more derivations from
the base translator class, but have no effect on the grammar.
(445 words)
Max: 400 words.
Assumed Knowledge
The reader is expected to understand Yacc grammars and basic OO
concepts as implemented in C++.
Motivation
The techniques presented in this paper came about from a project
where it was known in advance that there was a need to build at
least two tools out of a single grammar. The first was to
translate an application-specific language into C, and the second
was a pretty-printer for that language. This is often done with
two separate grammar files (using Yacc, these are “dot
Y” files) which differ not in syntax but in the semantic
code added to each grammar production. Was it possible to have a
single grammar file and use it in two different tools?
Why Grammars are Interesting
Parsing theory is one of the most powerful collections of tools
available to a programmer. It allows us to turn complex but
human-friendly input data into structured representations more
amenable to manipulation and analysis. The various types of
parsers may be subdivided in various ways. One common
subdivision is into recursive descent parsers and table
driven parsers. Recursive descent parsers are composed of a
number of mutually recursive functions which partition the input.
Table driven parsers use a table to drive a push-down state
machine which partitions the input; they tend to be smaller (but
not necessarily faster) than recursive descent parsers but
generating the tables is a complex task best done by a program,
such as yacc(1) or bison(1).
Computer
languages are compiled or interpreted or translated or analyzed
by first parsing the input text and forming tree representations
of the program. Various complex or simple manipulations are then
performed to do whatever it is the tool must do. Parsers are
only able to help with the first step, they can not greatly help
with the subsequent data manipulations.
Why Factories are Interesting
Factories provide a simple and powerful way of thinking about
things you know (and want to know) nothing about, or very little
about. This amorphous data hiding (not just simple
encapsulation) is what gives the technique its power. The
factory method pattern is an object-oriented design pattern.
Like other creational patterns, it deals with the problem of
creating objects (products) without specifying the exact class of
object that will be created. Factory method, one of the patterns
from the Design Patterns book, handles this problem by defining a
separate method for creating the objects, which subclasses can
then override to specify the derived type of product that will be
created. More generally, the term factory method is often used to
refer to any method whose main purpose is creation of objects.
(Wikipedia)
In this paper, the use of factories allows code reuse
between, say, a compiler and a pretty printer, or a variety of
code analysis tools. Large amounts of the machinery for
understanding the input is common to both. Languages like C and
C++ particularly need semantic analysis, most obviously for
types, before any kind of semantic tree can be constructed
from the syntax tree.
Combining Grammars and Factories
In the context of grammars, the use of factories means that the
expression node for addition can be specialized for many tasks,
and none of these tasks need affect the parser itself, because it
is operating with an abstract interface, and is elegantly
decoupled from the output side of whatever it is the tool is
doing. The pretty printer can print a plus symbol, and the
compiler can produce the right opcode, and so on. While more
tools require more derivations from the base expression class,
these have have no effect on the grammar.
The application of these methods apply equally to language
statements, type declaration, variable declarations, and all of
the other pieces which make up the richness of all but the
simplest of computer languages. For this reason, this paper
concentrates on a very small number of expressions and types.
The generalization for more types, more operators and more
statements, requires more space than is available, and is left as
an exercise for the reader.  A Short Polymorphism Diversion
A common implementation of expression trees in C looks similar to
the code below. The pattern has a struct with and ID member and
a union, selected by the ID. The expression interface include
file would look similar to this:
A Short Polymorphism Diversion
A common implementation of expression trees in C looks similar to
the code below. The pattern has a struct with and ID member and
a union, selected by the ID. The expression interface include
file would look similar to this:
typedef struct expr expr; struct expr {
enum opcode_t e_op;
enum type_t e_type;
union
{
expr *e__branch[2];
char *e__string;
int e__int;
double e__double;
symbol *e__symbol;
} e_u; };
expr *expr_alloc(int op); void expr_free(expr *ep); char
*expr_text(expr *ep); void expr_generate_code(expr *ep); expr
*expr_method_name(expr *ep); etc etc etc
Each of the related functions contains a switch statement. This
is example is a pretty printer:
#include "expr.h"
expr * expr_alloc(enum opcode_t op) {
expr *result;
result = new(expr);
result->e_op = op;
return result; }
void expr_generate_code(expr *e) {
switch(e->e_op)
{
case PLUS:
printf("(");
expr_generate_code(e->e_branch[0]);
printf(" + ");
expr_generate_code(e->e_branch[1]);
printf(")");
break;
case IDENT:
printf("%s", e->e_symbol->name);
break;
case INT_CONST:
printf("%d", e->e_int);
break;
case DOUBLE_CONST:
printf("%g", e->e_double);
break;
case CHAR_STRING:
printf("
break;
} }
etc etc
void expr_free(expr *ep) {
if (!ep)
return;
switch(ep->e_op)
{
case INT_CONST:
case DOUBLE_CONST:
case CHAR_CONST:
break;
case IDENT:
case CHAR_STRING:
free(ep->e_string);
break;
case PLUS:
etc etc etc
expr_free(ep->e_branch[1]);
/* fall through... */
case UNARY_MINUS:
etc etc etc
expr_free(ep->e_branch[0]);
break;
}
free(ep); }
This code is sub-optimal in its use of storage space, as every
expression node is allocated as enough space to hold the largest
of the variants. A second problem is to do with the code in
maintenance mode. The availability of all union variants to all
methods can result in parasitic reuse of union members rather
then going through all of the tedious business of adding another
union member. This results in a mine-field of problems waiting
to happen when a later maintainer innocently tries to alter a
union member.
A Better Way
In object oriented terms, the above code is best seen as an anti-pattern. A far better object oriented implementation
uses virtual methods. The equivalent code in C++ code is
more verbose, but it is less fragile in maintenance mode, and as
fast or faster, and uses slightly less storage. The union ID
becomes the vptr (the pointer to the appropriate class's
virtual
method table).
class expression { public:
virtual ~expression();
expression();
virtual char *text() = 0;
virtual expr *optimize() = 0;
virtual void generate_code() = 0;
etc etc etc };
Each expression type is then derived form this abstract
expression base class. The interface refines the base class:
class expression_plus:
public expression { public:
virtual ~expression_plus();
expression_plus(expression *, expression *);
char *text();
expr *optimize();
void generate_code();
etc etc etc private:
expression *lhs;
expression *rhs; };
A pretty printer implementation would look something like this:
expression_plus::~expression_plus() {
delete lhs;
delete rhs; }
expression_plus::expression_plus(expression *a1,
expression *a2) :
lhs(a1),
rhs(a2) { }
void expression_plus::generate_code() {
printf("(");
lhs->generate_code();
printf(" + ");
rhs->generate_code();
printf(")"); }
It is important to remember that while the C++ code is
necessarily rather more verbose than the C code (especially if
one strictly disciplines oneself to a single class per source
file), it is also more sparing of memory, and it can often
execute more rapidly. The greatest advantage, however, is
the increased robustness during the maintenance phase. This
arises from the inaccessibility (the complete ignorance of) the
instance variables of other derived classes (which the C union
was used to remember).
The code is also easier to read because the union member
machinery is no longer needed, and no longer adding visual
clutter to the implementation.
Writing Parsers
Parser theory is often taught with recursive descent parsers
first. This gives student programmers a taste of the actual
complexity of the task. The example to be used here is one
tiny portion of the expression processing necessary in a computer
language parser.
expression * parse_expression_addprec() {
for (;;)
{
expression *lhs = parse_expression_mulprec();
switch (current_token)
{
case '+':
next_token();
expression *rhs = parse_expression_mulprec();
lhs = new expression_addition(lhs, rhs);
break;
case '-':
blah blah blah
default:
return lhs;
}
} }
Hand written recursive descent parsers have a number of problems.
Firstly, they are very big. The machinery to accomplish the
parsing consists of a large amount of code, all of it necessary,
with enough self-similarity to suggest re-usability and enough
differences to make this unlikely. Second, in a recursive
descent parser, it is difficult to see which parts of the code
are implementing the syntax, and which parts of the code are
implementing the semantics. This often leads to ugly compromises
and context sensitive grammars, in the name of pragmatism. The
#define mechanism in C and C++ is a good (or is that bad?)
example:
#define FIRST(a) blah blah #define
SECOND (a) yada yada
The original context sensitive hack is to test for an opening
parentheses immediately after the define's name. These
days the cracks are papered over with a more elegant formulation
involving white space as tokens which are considered by the
preprocessor, but discarded before the parser proper sees them.
Another problem with hand written recursive descent parsers
is that they are fragile. If maintained by a programmer with
less parser theoretical knowledge than the original author, it is
possible to break them pretty throughly during the maintenance
phase. Similarly, a group writing such a parser risks serious
breakage for each commit.
Thorough testing, of course, would
go a long way towards ameliorating this fragility, but given the
combinatorial complexity possible, this is challenging.
Unfortunately, it is often the case that the original test suite
by the original programmer becomes detached from the sources, and
so regression testing is nonexistent in far too many cases. This
is how C compiler validation companies can make a living, and C++
must be even more lucrative.
Parser Generators
Now that the challenge of manually implemented recursive descent
parsers is appreciated, we can move on to parser generator tools,
such as yacc(1) and bison(1). These tools permit a
greater level of complexity, and more rapid comprehension and
maintenance. While these tools simplify the task of writing a
grammar recognizer, they have little effect on the complexity of
the subsequent processing performed on the actual content.
Note that while many generated parses are table driven (and this
is often exploited for stack-splitting GLR parsers) some
generators generate recursive descent parsers (for example, Packrat
parsers) from the grammar specification.
The above
long-winded manual recursive descent parser becomes the more
terse Yacc example:
expression: expression '+' expression
{ $$ = build_addition_expression($1, $3); }
The first line is the grammar production. It says that an
expression can be defined as one expression plus another
expression. At some other point in the definition, each
operator is assigned a precedence. Should a precedence bug be
found, it is simply fixed by altering the precedence definitions,
and then regenerating the code. In the manual recursive descent
case, the erroneous code must be correctly extracted from one
location in the code, and then carefully inserted at the correct
location.
The second line of the above example {enclosed in
curly braces} is the semantic action attached to the grammar
production. When such a production is matched in the input, this
fragment of C code is executed.
One File, One Language
One of the most difficult things about parser generator tools is
beautifully demonstrated by the GNU C Compiler's grammar
specifications. The actual grammar is visually overwhelmed by
the sheer quantity of C code attached to each production.
|
Here is an example fragment from gcc-2.95 | | And here is the same
code from gcc-3.4.6 |
primary:
IDENTIFIER
{
$$ = lastiddecl;
if (!$$ || $$ == error_mark_node)
{
if (yychar == YYEMPTY)
yychar = YYLEX;
if (yychar == '(')
{
/* Ordinary implicit function declaratio
$$ = implicitly_declare ($1);
assemble_external ($$);
TREE_USED ($$) = 1;
}
else if (current_function_decl == 0)
{
error ("`%s' undeclared here (not in a f
IDENTIFIER_POINTER ($1));
$$ = error_mark_node;
}
else
{
if (IDENTIFIER_GLOBAL_VALUE ($1) != erro
|| IDENTIFIER_ERROR_LOCUS ($1) != cu
{
error ("`%s' undeclared (first use i etc
etc etc |
| primary:
IDENTIFIER
{
if (yychar == YYEMPTY)
yychar = YYLEX;
$$ = build_external_ref ($1, yychar == '(');
}
| CONSTANT
| STRING
| FUNC_NAME
{ $$ = fname_decl (C_RID_CODE ($$), $$); }
| '(' typename ')' '{'
{
start_init (NULL_TREE, NULL, 0);
$2 = groktypename ($2);
really_start_incremental_init ($2);
}
initlist_maybe_comma '}' %prec UNARY
{
tree constructor = pop_init_level (0);
tree type = $2;
finish_init ();
if (pedantic && ! flag_isoc99)
pedwarn ("ISO C90 forbids compound literals");
$$ = build_compound_literal (type, constructor);
} etc etc etc |
You will notice that most of the left hand side is C code, and
that much, but not all, has been moved into a C function on the
right hand side.
Taking this approach to the limit,
completely replacing production body code with an external
function for each production, and to collect these functions into
one (or more) separate source files. In essence, one is a Yacc
file, and one is a C file.
%right ASSIGN /* lowest precedence */ %left
PLUS /* highest precedence */
%%
expression
: IDENTIFIER
{ $$ = build_expression_identifier($1); }
| expression PLUS expression
{ $$ = build_expression_addition($1, $3); }
| expression ASSIGN expression
{ $$ = build_expression_assignment($1, $3); }
| etc etc
;
Something interesting happens when you think about implementing
these external functions as methods of a single class.
%{ translator *context; %}
%right ASSIGN /* lowest precedence */ %left PLUS /* highest
precedence */
%%
expression
: IDENTIFIER
{ $$ = context->expression_identifier($1); }
| expression PLUS expression
{ $$ = context->expression_addition($1, $3); }
| expression ASSIGN expression
{ $$ = context->expression_assignment($1, $3); }
| etc etc
;
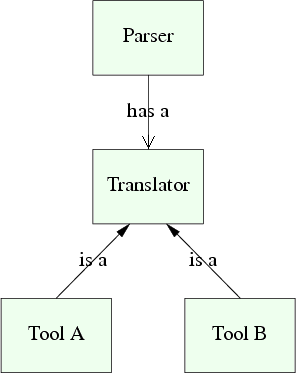 When mixed
with simple polymorphism (make them all virtual methods)
it becomes possible to leave the grammar untouched, and yet
derive completely different content processing classes.
When mixed
with simple polymorphism (make them all virtual methods)
it becomes possible to leave the grammar untouched, and yet
derive completely different content processing classes.
/**
* The translator abstract base class represents the semantics
* actions to be applied to the grammar as it is parsed.
*
* It is called a translator because it reads its input, and
translates
* it into some other representation. It could be simply
prettier, it
* could be an executable file, it could be a dot file for
drawing call
* graphs with dotty(1), etc.
*/ class translator { public:
virtual ~translator();
blah blah blah
/**
* The expression_addition method is used to build a
suitable
* expression node for the given operands.
*
* @param lhs
* The left hand operand of the addition expression.
* @param rhs
* The right hand operand of the addition expression.
* @returns
* A dynamically allocated derived expression instance.
*/
virtual expression *expression_addition(expression *lhs,
expression *rhs) = 0;
blah blah blah };
Once coded, it becomes apparent that each method looks
suspiciously like a factory method. That is, it could return any
number of different expression node instances, provided they are
derived from the expression base class. For example, a pretty
printer may return an expression node which will later print
itself with the proper parentheses and spaces around the
operator. On the other hand, a compiler may return several
different expression types of nodes, depending on whether it is
integers to be added, or reals, or a string concatenation, and
these would each generate different opcodes. The translator
is an abstract factory. The interface exists to manufacture
suitable expression and statment nodes (etc). Derived
classes are specialized to manufacture tool specific objects, in
context.
Pretty Printer
The derived class for the pretty printer looks something like
this:
class pretty_printer:
public translator { public:
virtual ~pretty_printer();
blah blah blah
// See base class for documentation.
expression *expression_addition(expression *lhs,
expression *rhs);
blah blah blah };
expression * pretty_printer::expression_addition(expression *lhs,
expression *rhs) {
return new expression_addition_pretty(lhs, rhs); }
And so on, down into the minutia of printing parentheses, and the
operands, and spaces, and plus symbols. This is repeated for
each of the other operators in the input language.
Compiler
The compiler, however, needs behave differently:
expression *
compiler::build_addition_expression(expression *lhs,
expression *rhs) {
switch (PAIR(lhs->get_type(), rhs->get_type()))
{
case PAIR(type_integer, type_integer):
return new expression_addition_integer(lhs, rhs);
case PAIR(type_real, type_real):
return new expression_addition_real(lhs, rhs);
case PAIR(type_integer, type_real):
return new expression_addition_real(
new expression_cast_real_from_integer(lhs), rhs);
case blah:
blah blah
}
yyerror("invalid types for addition");
return new expression_error(); }
Again, this is repeated for each of the operators of the
language.
Assignments
Expressions on left hand side of an assignment are different than
expression on the right hand side. Left hand expressions need to
calculate storage locations, right hand expressions need to
calculate values. But how does the grammar know which is which?
A traditional response to this problem is to distinguish
lvalue and rvalue expressions in the grammar
itself. This has the virtue of simplicity, but it makes for poor
error messages.
In Pascal, the following contains an error:
program example; var x: integer; begin
x = 7 end.
assignment_statement
: left_expression ASSIGN right_expression
{ $$ = context->statement_assign($1, $3); }
; |
statement
: expression
{ $$ = context->statement_expression($1); }
;
expression
: expression ASSIGN expression
{ $$ = context->expression_assign($1, $3); }
; |
| ucsdpsys_compile:
example.pas: 4: syntax error | ucsdpsys_compile: example.pas: 4:
statement expression not void as it should be, did you mean to
use an assignment (written ":=") instead of an equality test
(written "=")? |
The right hand error message is much more informative for the
user. This is a common mistake, now that so many languages have
adopted C-like syntax. Informative error messages in common
situations are never a waste of time. The improved error
messages is accomplished by moving the error out of the syntax
and into the semantics. But it raises another issue...
Turning Loads into Stores
If the meaning of an expression is moved into the semantics, it
means that the actual use of the expression (in the commonest
case, an identifier) must be deferred until more information is
available. In some cases, such as a pretty printer, this
distinction not important.
%right ASSIGN /* lowest */ %left PLUS /* highest */
%% expression
: IDENTIFIER
{ $$ = context->expression_identifier($1); }
| expression ASSIGN expression
| expression PLUS expression
| etc etc
;
expression * translator_compile::expression_identifier(const char
*name) {
return new expression_identifier_compile(name); }
When the grammar sees an identifier, it is a left hand identifier
or a right hand identifier? This is irrelevant for a pretty
printer, but a compiler needs to know if it is to generate load
opcodes or store opcodes. As the commonest use of
expressions are as right hand side expressions, we have the
translator create load-expressions for identifiers and array
accesses, etc. When we discover an expression is actually
on the left hand side, we will have to synthesize a left hand
side expression from the right hand side expression.
The
grammar is just as we have been using, above, for implementing
other operators:
expression
: expression ASSIGN expression
{ $$ = context->expression_assign($1, $3); }
The implementation of the method would look something like this:
expression *
translator::expression_assign(expression *lhs, expression *rhs) {
if (lhs is an integer variable)
{
return expression_assign_integer_factory(
lhs->get address, rhs);
}
if (lhs is an integer array element)
{
return expression_assign_integer_factory(
lhs->get address, rhs);
}
if (lhs is a string variable)
{
return expression_assign_string_factory(
lhs->get address, rhs);
}
etc etc etc
yyerror("left hand side of assignment inappropriate");
return new expression_error(); }
This is a repeat of the same anti-pattern as before. In each
case we are dispatching on the type of the left hand side. Now,
we could use down-casts, but it turns out this is unnecessary.
Recall that we replaced the e_op with a vptr.
The correct way to do this is to ask the left hand side, it
already has a vptr.
expression
: expression ASSIGN expression
{ $$ = $1->assignment_factory($3); }
This is accompanied by a suitable virtual factory method, not in
the translator class hierarchy, but in the
expression abstract base class.
class expression {
blah blah public:
virtual expression *assignment_factory(expression
*rhs);
blah blah };
In this case, we do not make assignment_factory a pure
virtual method. Instead, the default implementation emits an
error message, because the vast majority of expression nodes
(e.g. arithmetic operators) may not be used on the left
hand side of an assignment.
expression
* expression::assignment_factory(expression *rhs) {
yyerror("left hand side of assignment inappropriate");
return new expression_error(); }
This results in far more elegant code. It reads better, it is
smaller, it is faster, and the error messages come almost for
free. And best of all, it has no casts (safe or unsafe) and does
not ever need to have access to the private instance variables of
any expression node. On first inspection, it may appear that
the translator may require the ability to intervene, rather than
directly calling an expression method. Recall, however, that the
translator created the expression instance, and thus has complete
control over the expression's assignment factory method. In
practice, this is entirely sufficient.
Additional uses
This solution may also be used when dealing with
-
function calls —
lhs(rhs)
-
the dot operator for accessing record fields —
lhs.rhs
-
array index expressions —
lhs[rhs]
-
tree re-writing optimizations within the compiler
The details are left as an exercise for the reader.
Double Trouble
The reader will have already noticed an inconsistency. The use
of the PAIR macro in the code generation of the addition
operator is another example of polymorphism done manually.
This switch (PAIR(blah,
blah)) mechanism would be repeated again and
again, for each manipulation which had to be performed on the
expression. Within a compiler this could be a method to
recursively test for constant-ness, or an optimize method to
recursively evaluate constant expressions at compile time,
etc. Here is an example of how it is often
implemented: void
expression_plus_compile::generate_code() {
lhs->generate_code();
rhs->generate_code();
switch (PAIR(lhs->get_type(), rhs->get_type()))
{
case PAIR(TYPE_INTEGER, TYPE_INTEGER):
emit(OP_ADI);
break;
case PAIR(TYPE_REAL, TYPE_INTEGER):
emit(OP_FLT);
emit(OP_ADR);
break;
case PAIR(TYPE_INTEGER, TYPE_REAL):
emit(OP_FLO);
emit(OP_ADR);
break;
case PAIR(TYPE_REAL, TYPE_REAL):
emit(OP_ADR);
break;
} }
The more desirable implementation would have a separate
derived class for each of the resulting opcodes, one for adding
integers, one for adding reads, one for string concatenation,
etc. Even within a compiler, without using a pretty
printer as a straw man, the
translator::addition_expression method should return
instances of several different derived expression
classes.
That is, we choose amongst the alternatives, not at method
execution time, but at object instantiation time.
void
expression_plus_integer_compile::generate_code() {
lhs->generate_code();
rhs->generate_code();
emit(OP_ADI); }
void expression_plus_real_compile::generate_code() {
lhs->generate_code();
rhs->generate_code();
emit(OP_ADR); }
This has the advantage of having less code to
maintain, performing a whisker faster as a result. Each of the
parallel switch bodies are now segregated into their own class,
the switch value need not be calculated over and over again, and
the sparse switch machinery is no longer required. There
needs to be something for the implicit casts, too, but they don't
need their own addition objects. This leaves one remaining
problem: how to we get rid of the switch in the factory method
itself. After all, something must decide which expression
addition derivative to instantiate. We could use the
std::pair template, but that is just as ugly. The
solution is a multi-method, dispatching from more than one
vptr at a time, something C++ currently has no direct
support for. A very simple, table driven technique may be used,
with the advantage of re-usability, and consistent error messages
for users as well. The mechanism is to use a method pointer for
the appropriate factory method to call from the table match. The
important point to remember is that method pointers can point to
virtual methods just as well as non-virtual methods.
class translator {
blah blah private:
binary_dispatch op_add;
blah blah };
translator::translator() :
add_op("addition") {
add_op.append(type_integer::is_a, type_integer::is_a,
&translator::addition_expression_integer);
add_op.append(type_real::is_a, type_real::is_a,
&translator::addition_expression_real);
add_op.append(type_real::is_a, type_integer::is_a,
&translator::addition_expression_real_integer);
etc }
The add_op instance variable is used to remember the
list of expression tests to perform represented by pointers to
functions or class methods, and a method pointer to another
factory method in the translator_compiler class,
e.g. the addition_expression_real method.
expression *
translator_compiler::addition_expression(expression *lhs,
expression *rhs) {
return add_op.lookup(lhs, rhs); }
The actual application of this is rather an anticlimax, because
the lookup method takes care of finding the appropriate
factory and calling it. If no table entry matches, a suitable
error message is produced, and a special “error”
expression instance is returned. Where implicit type
promotions may occur, e.g. adding an integer and a real,
additional table entries can be added for the various
combinations, which build a type casting expression node to
promote one or other argument, as required, and then call
appropriate “real” factory method, which takes two
arguments of the same type. expression *
translator::addition_expression_real_integer(expression *lhs,
expression *rhs) {
rhs = cast_integer_to_real_factory(rhs);
return addition_expression_real(lhs, rhs); }
In languages where users may define
operators taking new types of arguments, e.g. C++
operator+ definitions, this can be implemented by more
rows being added to the add_op table during the compile,
in addition to those in the translator constructor.
A similar mechanism can be used for unary operators. Also, the
tests on each row can be as complicated or simple as required.
Conclusion
Using them methods presented in this paper, software may be
written which separates language syntax from language semantics,
permitting significant reuse of front-end grammars by several
related tools, by using the factory method OO design pattern,
called by each grammar production. The same pattern can be
used to handle the more complicated cases of assignment tree
rewriting and array indexing, not via the translator object but
via the left hand expression object. Working out where the
virtual method should be implemented can be seen by looking for a
switch on an ID. There are some cases where the switch (or
deep if-then-else chain) has more than one dimension.
Polymorphism is still appropriate, but a multi-method is
required.
Open Source Projects
There are two open source (GPL) projects which are using the
techniques in this paper: - The UCSD p-System Cross Compiler project provides a Pascal cross
compiler for producing UCSD p-System code files on Posix hosts,
such as Linux. This started as a nostalgic trip down memory
lane, and turned into a serious piece of retro-computing.
-
The Tickle project is an open-source implementation of a
compiler for the domain-specific language called Transaction
Control Language (TCL).
Acknowledgements
This paper would not have been possible without the encouragement
and keen insights of of Robert Collins, Erik de Castro Lopo and
probably many other people whose ears I have bent repeatedly on
this subject for the last year to so.
|